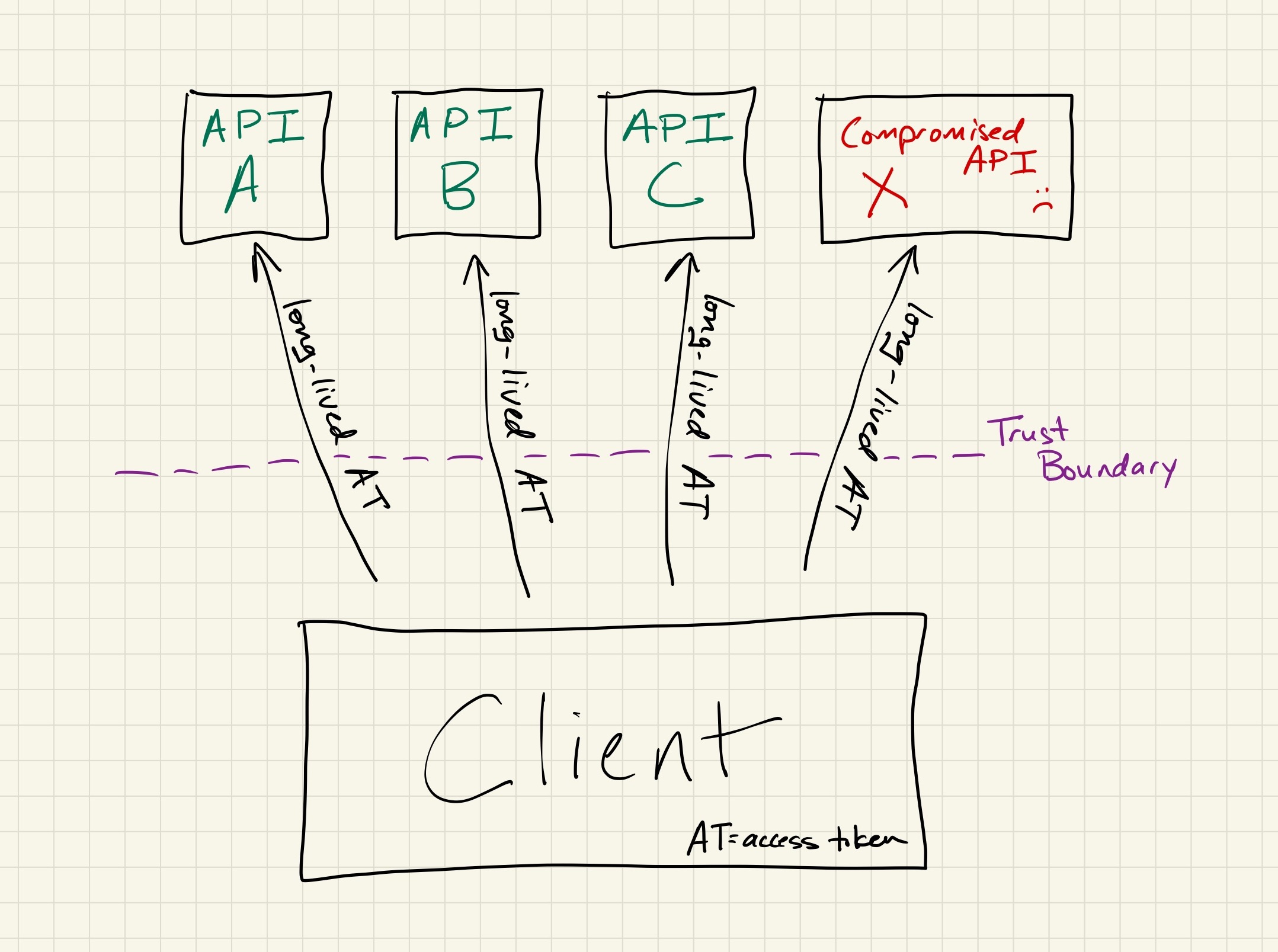
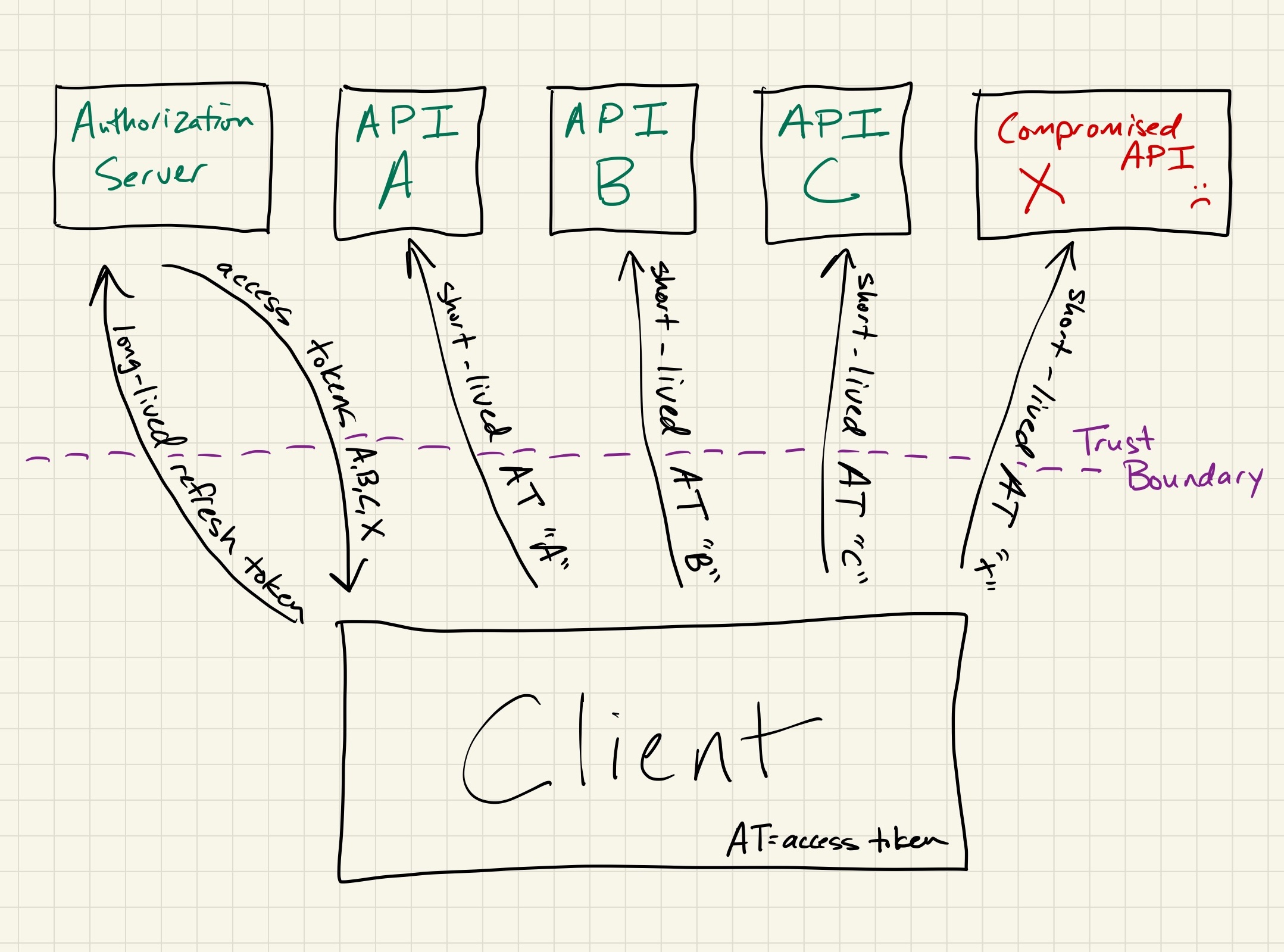
Why would you want to use long-lived refresh tokens that generate short-lived access tokens as commonly seen in OAuth 2.0, versus long-lived access tokens? Aren’t you simply replacing one long-lived token with another?
Before diving into everything, some vocabulary to clarify:
Definitions
Access token: a secret token that clients can exchange with servers to get access to their resources. These can either be long-lived (and potentially never expire), or short-lived, where they might last for only hours to days.
Refresh token: a long-lived secret token that itself does not grant access to resources, but which instead can be exchanged with an authorization server for a short-lived access token
Authorization server: the server(s) which consumes refresh tokens and issues access tokens
Resource server: the server(s) which consume and validate access tokens, and grants access to authorized services if valid
Why Refresh Tokens
There isn’t any one huge advantage that immediately stands out in favor of refresh tokens. Instead, there are a number of incremental improvements that add up towards making it the overall superior design.
It simplifies revocation, for much the same reason that digital certificates (as used in HTTPS) are slowly changing to be 90 days by default. Long-lived access tokens require that all systems that receive the access token need to be constantly checking a central server to see if the token has been revoked.
When using a refresh token, only the authorization server needs to check for revocation, and the self-contained stateless nature of the short-lived access tokens they generate means that systems which consume them only need to check that they haven’t expired and that their signature is valid. While this doesn’t matter as much in smaller scale systems where there are few resource servers, it both eases development as systems grow and results in sometimes significant performance gains.
Short-lived access tokens limit the impact of them being leaked or compromised. While refresh tokens tend to live on and only transit between two endpoints — the client and authorization server — access tokens are transmitted to every single resource server that requires them.
As a result of violating the core security axiom of minimizing the frequency at which long-lived tokens cross trust boundaries, it becomes immensely more difficult to secure long-lived access tokens from compromise.
even if the compromised system is repaired, all access tokens sent to it will forever be untrustworthy
With a refresh token design, the authorization server and its storage can be robustly secured, with access to those systems extremely limited. On the other hand, resource servers are run by dozens of teams with a wide range of technology stacks and security postures. As a result, resource servers are far more likely to leak an access token through improper logging, poor access control, analytics, attacker compromise, etc.
In the event of a leak or compromise, the impact is far more limited with refresh tokens than it is with long-lived access tokens. Instead of simply fixing the underlying issue and letting the short-lived access tokens expire, long-lived access tokens also require you to either revoke all affected tokens or constantly monitor for abuse on an indefinite basis.
access tokens disclosed to a repaired but previously compromised system will expire quickly without manual intervention
Refresh tokens provide incremental improvements to client security, as allowed by their intermittent use. As long-lived access tokens get used across numerous services on every request, it is necessary that they live in memory. Refresh tokens can live in secure enclaves or keychains, and their infrequent use in both memory and on the network provides some mitigation against transient attacks.
Refresh tokens allow for flexibility in future access grants. When using a refresh token, the authorization server is free to either add or remove individual permissions granted to access tokens as time goes on and system designs change. The immutable nature of long-lived access tokens adds significant complexity to permission changes, short of turning them into a quasi-refresh token by exchanging them for different access tokens or by using them to query a centralized permission store.
Although a pretty minor benefit, the nature of refreshing access tokens allows abuse teams to build better heuristics around abuse detection. Having a history of refresh and access token behavior allows more powerful anti-abuse detections than simply using a long-lived access token alone.
Why Not Refresh Tokens
While there are a number of upsides to using refresh tokens, there are also some downsides:
Increased client complexity as a result of having to implement the logic to exchange refresh tokens for access tokens. Although this is typically a one-time cost and is often abstracted away by OAuth libraries, it nevertheless adds time to build to initial client implementations when compared to a simple access token.
The very nature of authorization servers means that they act as a single point-of-failure. This can be mitigated to a significant degree by tweaking access token lifetimes, building redundancy and resiliency around authorization servers, and by having clients request refreshed access tokens comfortably before expiration to avoid temporary “blips.”
However, the very design of having a centralized authorization server gating the creation of new access tokens means that long outages on these systems can nevertheless result in all dependent resource servers being unable to operate.
Note that long-lived access tokens have their own single point-of-failure in their need for centralized revocation servers, although systems are commonly designed to “fail open” if their revocation status servers are unavailable despite the trade-off in security that this entails.
Conclusion
I hope this helps to clarify what the upsides and downsides of refresh tokens are, and why modern applications tend to be designed around refresh tokens. While they aren’t perfect, the combined benefits of using refresh tokens and short-lived access tokens are pretty substantial.
Additional Information
Refresh tokens, as described in the OAuth 2.0 specification
Cache-Control is one of the most frequently misunderstood HTTP headers, due to its overlapping and perplexingly-named directives. Confusion around it has led to numerous security incidents, and many configurations across the web contain unsafe or impossible combinations of directives. Furthermore, the interactions between various directives can have surprisingly different behavior depending on your browser.
The objective of this document is to provide a small set of recommendations for developers and system administrators that serve documents over HTTP to follow. Although these recommendations are not necessarily optimal in all cases, they are designed to minimize the risk of setting invalid or dangerous Cache-Control directives.
Recommendations
Recommendation
Safe for PII
Use Cases
Header Value
Don't cache (default)
Yes
API calls, direct messages, pages with personal data, anything you're unsure about
When you're unsure, the above is the safest possible directive for Cache-Control. It instructs browsers, proxies, and other caching systems to not cache the contents of the request. Although it can have significant performance impacts if used on frequently-accessed public resources, it is a safe state that prevents the caching of any information.
It may seem that using no-store alone should stop all caching, but it only prevents the caching of data to permanent storage. Many browsers will still allow the caching of these resources to memory, even if it doesn't write them to disk. This can cause issues where shared systems may contain sensitive information, such as browsers maintaining cached documents for logged out users.
Although no-store may seem sufficient to instruct content delivery networks (CDNs) to not cache private data, many CDNs ignore these directives to varying degrees. Adding private in combination with the above directives is sufficient to disable caching both for CDNs and other middleboxes.
Static, versioned resources:max-age=n, immutable
If you have versioned resources such as JavaScript and CSS bundles, this instructs browsers (and CDNs) to cache the resources for n seconds, while not purging their caches even when intentionally refreshing. This maximizes performance, while minimizing the amount of complexity that needs to get pushed further downstream (e.g. service workers). Care should be taken such that this combination of directives isn't used on private or mutable resources, as the only way to "bust" the cache is to use an updated source document that refers to new URLs.
The value to use for n depends upon the application, and is ideally set to a bit longer than the expected document lifetime. One year (31536000) is a reasonable value if you're unsure, but you might want to use as low as a week (604800) for resources that you want the browser to purge faster.
Infrequently changing public resources or low-risk authenticated resources:max-age=n
If you have public resources that are likely to change, simply set a max-age equal to a number (n) seconds that makes sense for your application. Simply using max-age will allow user agents to still use stale resources in some circumstances, such as when there is poor connectivity.
There is no need to add must-revalidate outside of the unlikely circumstance where the resource contains information that must be reloaded if the resource is stale.
Directives
For brevity, this only covers the most common directives used inside Cache-Control. If you are looking for additional information, the MDN article on Cache-Control is pretty exhaustive. Note that its recommendations differ from the recommendations in this document.
max-age=n (and s-maxage=n)
instructs the user agent to cache a resource for n seconds, after which time it is considered "stale"
s-maxage works the same as max-age, but only applies to intermediary systems such as CDNs
no-store
tells user agents and intermediates not to cache anything at all in permanent storage, but note that some browsers will continue to cache in memory
no-cache
contrary to everything you would think, does not tell browsers not to cache, but instead forces them to check to see if the resource has been updated via ETag or Last-Modified
essentially the same as max-age=0, must-revalidate
must-revalidate
forces a validation when cache is stale – this can mean that browsers will fail to use a cached resource if it is stale but the site is down
generally only useful for things like HTML with time-specific or transactional data inside
if max-age is set, must-revalidate doesn't do anything until it expires
immutable
indicates that the body response will never change
when combined with a large max-age, instructs the browser to not check to see if it's still valid, even when user purposefully chooses to refresh their browser
public
indicates that even normally non-cacheable responses (typically those requiring Authorization) can be cached on public systems, such as CDNs and proxies
recommended to not use unless you're certain, as it's probably better to waste bytes than to make the mistake of having a private document get cached on a CDN
private
indicates that caching can happen only in private browser (or client) caches, not on CDNs
note that this wording can be deceiving, as “private” documents are frequently cached on CDNs, with high-entropy URLs
documents behind authentication are an example of a good target for the private directive
stale-while-revalidate=n
instructs browsers to use cached resources which have been stale for less than n seconds, while also firing off an asynchronous request to refresh the cache so that the resource is fresh on next use
can provide a decent performance boost, as long as you're careful to avoid any issues where you require multiple resources to be fresh in a synchronized manner
browser support is still limited, so if you decrease max-age to compensate, note that it will affect browsers that don't yet support stale-while-revalidate
Common anti-patterns and pitfalls
Surveys of Cache-Control across the internet have identified numerous anti-patterns in broad usage. This list is not meant to be extensive, but simply to demonstrate how complex and sometimes misleading that the Cache-Control directive can be.
max-age=604800, must-revalidate
While there are times that max-age and must-revalidate are useful in combination, for the most part this is saying that you can cache a file but then must immediately distrust it afterwards even if the hosting server is down. Instead use max-age=604800, which says to cache it for a week while still allowing the use of a stale version if the resource is unavailable.
max-age=604800, must-revalidate, no-cache
no-cache tells user agents that they must check to see if a resource is unmodified via ETag and/or Last-Modified with each request, and so neither max-age=604800 nor must-revalidate do anything.
pre-check=0, post-check=0
You still see these directives appearing in Cache-Control responses, as part of some long-treasured lore for controlling how Internet Explorer caches. But these directives have never worked, and you're wasting precious bytes1 by continuing to send them.
Expires: Fri, 09 April 2021 12:00:00 GMT
While the HTTP Expires header works the same way as max-age in theory, the complexity of its date format means that it is extremely easy to make a minor error that looks valid, but where browsers treat it as max-age=0. As a result, it should be avoided in preference of the far more simple max-age directive.
Pragma: no-cache
Not only is the behavior of Pragma: no-cache largely undefined, but HTTP/1.0 client compatibility hasn't been necessary for about 20 years.
Glossary
fresh — a resource that was last validated less than max-age seconds ago
immutable — a resource that never changes, as opposed to mutable
stale — the opposite of fresh, a resource that was last validated more than max-age seconds ago
user agent — a user's browser, mobile client, etc.
validated — the user agent requested a resource from a server, and the server either provided an up-to-date resource or indicated that it hasn't changed from the last request
Prior to the release of the Mozilla Observatory in June of 2016, I ran a scan of the Alexa Top 1M websites. Despite being available for years, the usage rates of modern defensive security technologies was frustratingly low. A lack of tooling combined with poor and scattered documentation had led to minimal awareness around countermeasures such as Content Security Policy (CSP), HTTP Strict Transport Security (HSTS), and Subresource Integrity (SRI).
Since then, a number of additional assessments have done, including in October 2016, June 2017, and February 2018. All three surveys demonstrated clear and continual improvement in the state of web security. As a year has gone by since the last survey, it seemed like the perfect time to give the world wide web another assessment.
The overall growth in adoption continues to be encouraging, particularly the rise in the HTTPS and redirections to HTTPS. Overall, an additional 170,000 sites on the Alexa Top 1M now support HTTPS and about 190,000 of the top million websites have decided to do so automatically by redirecting to their HTTPS counterpart.
Subresource Integrity has also seen a sharp increase in uptake, as more and more libraries and content delivery networks work to make its usage a simple copy-and-paste operation. We've also see X-Content-Type-Options gain signicantly increased usage, particularly given that its usage enables cross-origin read blocking and helps protect against side-channel attacks like Meltdown and Spectre.
While the usage of Content Security Policy has continued to grow, it seems to be slowing down a bit. Tools like the Mozilla Laboratory make policy generation a lot easier, but it still remains extremely difficult to retrofit CSP to old and sprawling websites like so many of the top million.
Lastly, whether a result of policy changes in how the HTTP Strict Transport Security preload list is administered or some weird bug in my code, the percentage of the Alexa Top 1M contained in the preload list fell slightly. Oddly enough, of the 20,105 sites that set preload, only 5,540 of them are actually preloaded.
Mozilla Observatory Grading
Progress continues to be made amongst the Alexa Top 1M websites, but the vast majority still do not use Content Security Policy, Strict Transport Security, or Subresource Integrity. When properly used, these technologies can nearly eliminate huge classes of attacks against sites and their users, and so they are given significant weight in Observatory grading.
Here are the overall grades changes over the last year. Please keep in mind that what is being tested now isn't the same as what was being tested three years ago. An A+ in April 2016 was considerably easier to acquire than an A+ is now.
Grade
April 2016
October 2016
June 2017
February 2018
April 2019
% Change
A+
.003%
.008%
.013%
.018%
.028%
+58%
A
.006%
.012%
.029%
.011%
.014%
+26%
B
.202%
.347%
.622%
1.08%
1.48%
+37%
C
.321%
.727%
1.38%
2.04%
1.82%
-11%
D
1.87%
2.82%
4.51%
6.12%
4.62%
-24%
F
97.60%
96.09%
93.45%
90.73%
92.03%
+1.43%
It's interesting to notice growth at both the top and the bottom. Over the last year, Observatory tests have gotten more difficult, particularly with regards to loading JavaScript over protocol-independent URLs such as this:
<script src="//example.com/script.js">
As a result, the bifurcation in scores likely indicates that more sites have decided to take web security seriously while others at the tail have fallen further into failure.
The Mozilla Observatory recently passed an important milestone of 10 million scans and has now helped over 175,000 websites improve their web security.
That's a big number, but I would love to see it continue to grow. So please share the Observatory so that the web can keep getting safer. Thanks so much!
Released in 1997, Magic: The Gathering - BattleMage was a real-time strategy game by Acclaim Entertainment. Published for the PlayStation and PC, its gameplay was bears little resemblence to the Magic we know today. Nevertheless, it is filled with an incredible amount of lore from early Magic history.
Due to its age and rarity – as well as the storyline's many branching paths – this lore was long-since considered lost to the Vorthos community.
Given Magic’s return to Dominaria, and BattleMage's significance in cards such as Time of Ice, I thought it best to crawl through BattleMage's code to extract the lore contained within.
I do hope you enjoy these texts, which are ordered as they appear in the game. Please contact me if you notice any mistakes in the editing. Thanks!
Stories
The BattleMage, a story about Rahel, one of Serra’s angels
The Shadow Mage, a story about Freyalise and the Carthalions
Prior to the release of the Mozilla Observatory in June of 2016, I ran a scan of the Alexa Top 1M websites. Despite being available for years, the usage rates of modern defensive security technologies was frustratingly low. A lack of tooling combined with poor and scattered documentation had led to minimal awareness around countermeasures such as Content Security Policy (CSP), HTTP Strict Transport Security (HSTS), and Subresource Integrity (SRI).
Since then, a number of additional assessments have done, including in October 2016 and June 2017. Both of those surveys demonstrated clear and continual improvement in the state of internet security. But now that tools like the Mozilla Observatory, securityheaders.io and Hardenize have become more commonplace, has the excitement for improvement been tempered?
Improvement across the web appears to be continuing at a steady rate. Although a 19% increase in the number of sites that support HTTPS might seem small, the absolute numbers are quite large — it represents over 83,000 websites, a slight slowdown from the previous survey's 119,000 jump, but still a great sign of progress in encrypting the web's long tail.
Not only that, but an additional 97,000 of the top websites have chosen to be HTTPS by default, with another 16,000 of them forbidding any HTTP access at all through the use of HTTP Strict Transport Security (HSTS). Also notable is the jump in websites that have chosen to opt into being preloaded in major web browsers, via a process known as HSTS preloading. Until browsers switch to HTTPS by default, HSTS preloading is the best method for solving the trust-on-first-use problem in HSTS.
Content Security Policy (CSP) — one of the most important recent advances due to its ability to prevent cross-site scripting (XSS) attacks — continues to see strong growth. Growth is faster in policies that ignore inline stylesheets (CSS), perhaps reflecting the difficulties that many sites have with separating their presentation from their content. Nevertheless, improvements brought about by specification additions such as 'strict-dynamic' and policy generators such as the Mozilla Laboratory continue to push forward CSP adoption.
Mozilla Observatory Grading
Despite this progress, the vast majority of top websites around the web continue not to use Content Security Policy, Strict Transport Security, or Subresource Integrity. As these technologies — when properly used — can nearly eliminate huge classes of attacks against sites and their users, they are given a significant amount of weight in Observatory scans.
As a result of their low usage rates amongst top websites, they typically receive failing grades from the Observatory. But despite new tests and harsher grading, I continue to see improvements across the board:
Grade
April 2016
October 2016
June 2017
February 2018
% Change
A+
.003%
.008%
.013%
.018%
+38%
A
.006%
.012%
.029%
.011%
-62%
B
.202%
.347%
.622%
1.08%
+74%
C
.321%
.727%
1.38%
2.04%
+48%
D
1.87%
2.82%
4.51%
6.12%
+36%
F
97.60%
96.09%
93.45%
90.73%
-2.9%
As 976,930 scans were successfully completed in the last survey, a decrease in failing grades by 2.9% implies that over 27,000 of the top sites in the world have improved from a failing grade in the last eight months alone. Note that the drop in A grades is due to a recent change where extra credit points can no longer be used to move up to an A grade.
Thus far, over 140,000 websites around the web have directly used the Mozilla Observatory to improve their grades, indicated by making an improvement to their website after an initial scan. Of these 140,000 websites, over 2,800 have improved all the way from a failing grade to an A or A+ grade.
When I first built the Observatory at Mozilla, I had never imagined that it would see such widespread use. 6.6M scans across 2.3M unique domains later, it seems to have made a significant difference across the internet. I couldn't have done it without the support of Mozilla and the security researchers who have helped to improve it.
Please share the Mozilla Observatory so that the web can continue to see improvements over the years to come!